Ist Ihre Webseite KI-ready? Cloudflare-Standard im Selbsttest
Cloudflare hat einen offenen Standard für Agent-ready-Webseiten etabliert. Wir haben dawema.com geprüft, eine Lücke gefunden und gefixt. Was KI-ready wirklich bedeutet, welche fünf Kategorien zählen und wie KMU-Webseiten das umsetzen können.
KI-Agenten wie ChatGPT, Claude, Gemini oder neue autonome Assistenten konsumieren Webseiten anders als ein klassischer Google-Crawler. Sie wollen wissen, welche Dienste eine Webseite anbietet, welche Endpunkte sie aufrufen können, in welcher Form sie Inhalte am liebsten erhalten und ob sie überhaupt erwünscht sind.
Cloudflare ist mit Abstand einer der wichtigsten Web-Infrastruktur-Anbieter weltweit. Geschätzt 20 Prozent aller HTTP-Anfragen im Internet laufen durch ihre Netze, darunter Größen wie Discord, Shopify, OpenAI und unzählige Mittelständler. Wenn Cloudflare einen Standard veröffentlicht, hat das Gewicht: Was sie als richtig definieren, wird in der Praxis zur Norm. Genau das ist im April 2026 mit ihrem Vorstoß zu “Agent-Ready”-Webseiten passiert.
Im Rahmen der Agents Week 2026 am 17. April 2026 hat Cloudflare einen offenen Standard zusammengefasst und auf isitagentready.com einen Test-Service bereitgestellt, der Webseiten in fünf Kategorien gegen diesen Standard prüft und einen Agent-Readiness-Score von 0 bis 100 vergibt. Wir haben unsere eigene Seite, dawema.com, durch den Test geschickt, dabei eine konkrete Lücke gefunden und sie gleich behoben. Was wir dabei gelernt haben, ist das Thema dieses Beitrags.
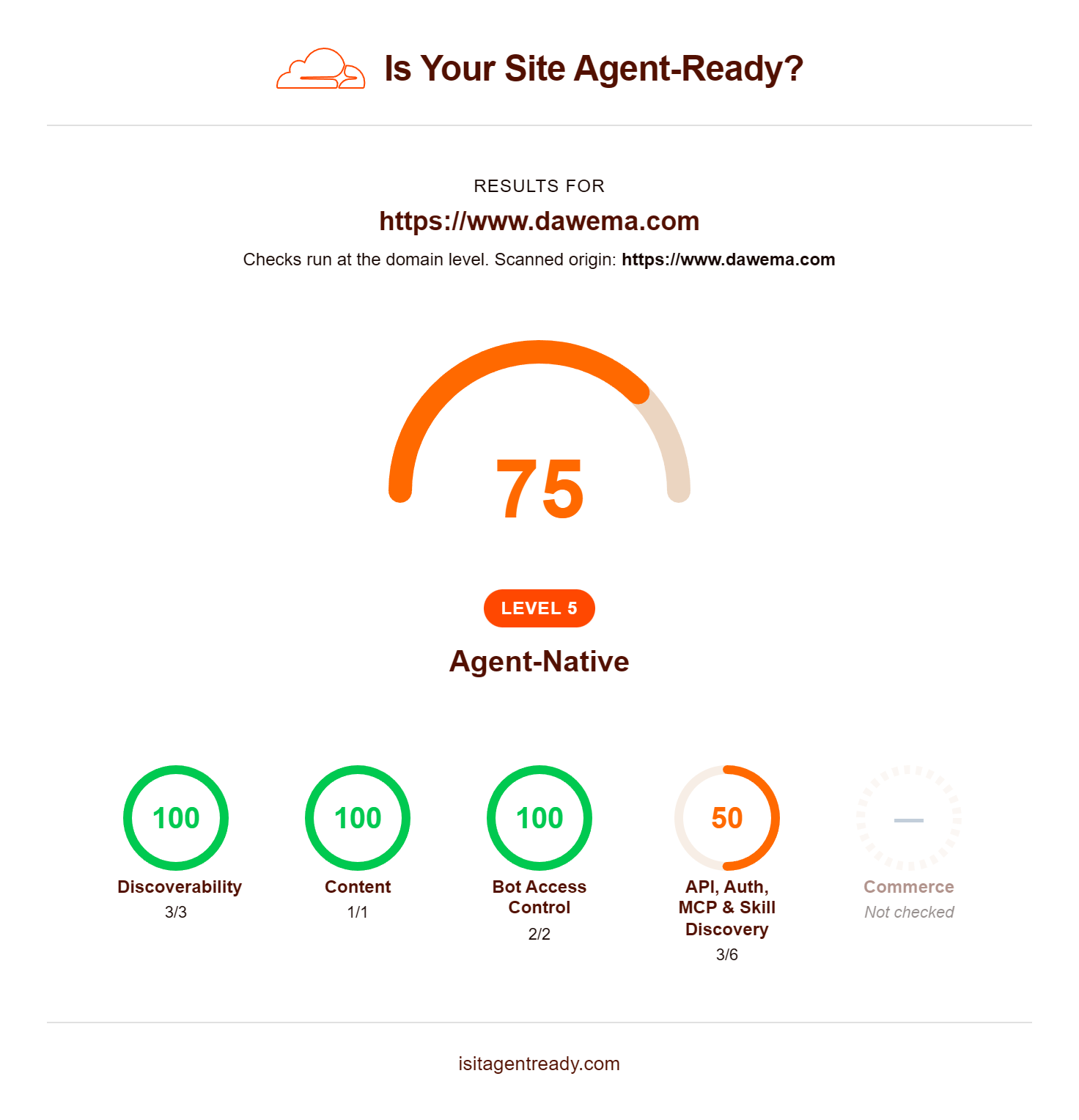
Unser Live-Ergebnis im Cloudflare-Test am 14. Mai 2026: Score 75/100, Level 5 “Agent-Native”, die zweithöchste Stufe von sechs. Bei einem erneuten Test im Juni lag der Wert bei 71/100, weil der Standard inzwischen zusätzliche Kategorien prüft, weiterhin Level 5. Wie wir dahin gekommen sind, steht weiter unten.
Wer ist Cloudflare und warum kann man dieser Quelle trauen?
Cloudflare ist ein US-amerikanisches Unternehmen mit Hauptsitz in San Francisco, das seit 2009 Web-Infrastruktur, CDN-Dienste, DDoS-Schutz und Sicherheits-Tools anbietet. Cloudflare ist börsennotiert (NYSE: NET) und beschäftigt nach eigenen Angaben mehr als 4.000 Mitarbeiter.
Die Marktstellung ist außergewöhnlich: Geschätzt 20 Prozent aller HTTP-Anfragen im Internet laufen über Cloudflare-Server. Zur Kundschaft gehören Discord, Shopify, Roblox, IBM, Marriott, NCR sowie über 30 Prozent der Fortune-1000-Unternehmen. Auch große KI-Anbieter wie OpenAI nutzen Cloudflare-Infrastruktur für ihre APIs.
Diese Reichweite macht Cloudflare zu einem De-facto-Standardsetzer für Web-Konventionen. Was Cloudflare als offenen Standard veröffentlicht (zum Beispiel der Content-Signal-Header oder die Agent-Readiness-Kriterien), wird in der Praxis von Webseiten-Betreibern weltweit übernommen und von Suchmaschinen-Anbietern anerkannt. Der Test selbst ist als kostenfreies Open-Source-nahes Tool aufgesetzt und erlaubt jedem Webseiten-Betreiber, ohne Account direkt zu prüfen, wie gut die eigene Webseite vorbereitet ist.
Die offizielle Ankündigung zum Standard und die Entwickler-Dokumentation sind frei einsehbar.
Die brisante Ausgangslage
Cloudflare hat zusammen mit dem Test-Tool auch Zahlen zum aktuellen Web-Stand veröffentlicht. Sie zeigen, wie dramatisch unvorbereitet die meisten Webseiten auf KI-Agenten sind:
- 78 Prozent der Webseiten haben überhaupt eine
robots.txt, die meisten davon aber nur mit Regeln für klassische Suchmaschinen-Bots. - Nur 4 Prozent deklarieren explizit, was KI-Modelle mit ihren Inhalten tun dürfen (Training, Suche, Antwort-Generierung).
- Nur 3,9 Prozent unterstützen Markdown Content Negotiation, also die Möglichkeit, Inhalte für KI-Agenten in einem effizienten Format auszuliefern.
- Weniger als 15 Webseiten weltweit haben aktuell eine MCP Server Card oder einen veröffentlichten API-Katalog. Das ist die Spitze des Eisbergs, an der sich entscheidet, ob ein KI-Agent direkt mit Ihrer Webseite interagieren kann.
Quellen: Cloudflare Blog: Introducing the Agent Readiness score und Cloudflare Developers Docs.
Warum KI-ready jetzt zählt
Vor zwei Jahren reichte es, wenn eine Webseite Google gefiel. Heute reicht das nicht mehr. Nutzer fragen ihre KI direkt nach Anbietern, Preisen, Erfahrungen und Empfehlungen. Die Antwort der KI entscheidet dann, welche Webseite empfohlen wird und welche unsichtbar bleibt. Webseiten, die KI-Agenten ihre Struktur, Inhalte und Endpunkte nicht maschinenlesbar anbieten, fallen aus dieser zweiten, schnell wachsenden Such- und Empfehlungs-Ebene heraus. Das gilt für AI-Overview bei Google, für Antworten in ChatGPT und Claude, für Perplexity und für jede neue Agent-Plattform, die in den nächsten Monaten kommt.
Konkret heißt KI-ready, dass eine Webseite drei Dinge gleichzeitig leisten muss:
- Sie ist für Menschen schön gestaltet und lesbar.
- Sie ist für klassische Suchmaschinen optimiert (Title, Description, strukturierte Daten, Sitemap).
- Sie ist für KI-Agenten maschinenlesbar zugänglich (llms.txt, agent-skills, MCP-Server-Card, robots.txt mit AI-Bot-Regeln, API-Katalog).
Die ersten beiden Punkte sind bekannt. Der dritte ist neu. Aus meiner Erfahrung in über 15 Jahren Webentwicklung wird er in den nächsten 12 bis 18 Monaten zum entscheidenden Differenzierungsmerkmal. Diese Einschätzung beruht auf der aktuellen Entwicklung bei AI-Overview, ChatGPT-Search, Claude und Perplexity, die alle einen wachsenden Anteil der Anbieter-Recherche übernehmen.
Die fünf Kategorien des Agent-Ready-Standards
Cloudflare bricht den Standard in fünf Kategorien herunter. Jede beantwortet eine konkrete Frage, die ein KI-Agent beim Besuch einer Webseite stellt.
1. Discoverability
Frage: „Was bietet diese Webseite an und wie finde ich heraus, was es alles gibt?”
Bausteine: robots.txt, sitemap.xml, HTTP-Link-Header. Eine Sitemap, die alle relevanten Unterseiten enthält. Eine robots.txt, die nicht nur die klassischen Suchmaschinen-Bots, sondern auch KI-Bots wie GPTBot, ClaudeBot, PerplexityBot und Googlebot-Extended explizit adressiert. Link-Header im HTTP-Response, die auf weitere Discovery-Endpoints verweisen.
2. Content Accessibility
Frage: „Kann ich die Inhalte effizient lesen oder muss ich das gesamte HTML einer Seite verarbeiten?”
Hier geht es um Markdown Content Negotiation: Wenn ein Agent den Header Accept: text/markdown setzt, sollte der Server eine reine Markdown-Version der Seite liefern. Das spart erhebliche Token-Budgets bei der KI und liefert klareren Kontext. Für KMU-Webseiten ist das aktuell die fortgeschrittenste Ebene und nicht zwingend Pflicht. Aber sie wird in den nächsten Monaten an Bedeutung gewinnen.
3. Bot Access Control
Frage: „Darf ich diese Inhalte lesen, und wenn ja, was darf ich damit machen?”
Hier liegt einer der wichtigsten Punkte: Die robots.txt sollte explizit klarstellen, welche KI-Bots Zugriff haben dürfen und ob die Inhalte für Suche, Antworten oder Training genutzt werden dürfen. Cloudflare hat dafür den Content-Signal-Header eingeführt, der drei Werte annehmen kann:
ai-train=yes|no: Inhalte dürfen für Modelltraining genutzt werden, oder eben nicht.search=yes|no: Inhalte dürfen in Suchergebnissen erscheinen.ai-input=yes|no: Inhalte dürfen als Eingabe für KI-Antworten verwendet werden.
Eine durchdachte Konfiguration ist ai-train=no, search=yes, ai-input=yes: Suche und Antworten erlaubt, Training nicht. Das schützt das geistige Eigentum, ohne die Sichtbarkeit zu kosten.
4. Protocol Discovery
Frage: „Welche Dienste bietest du an, die ich als Agent direkt aufrufen kann?”
Bausteine: /.well-known/agent-skills/index.json, /.well-known/mcp/server-card.json, /.well-known/api-catalog, OpenAPI-Beschreibungen. Diese Endpunkte definieren in strukturierter Form, welche Aktionen ein KI-Agent automatisiert ausführen kann. Beispiel für DAWEMA: ein Agent kann über /api/contact eine Kontaktanfrage senden oder über /api/demo-request einen Demo-Anruf anfordern.
5. Commerce
Frage: „Wie kann ich als Agent bezahlte Transaktionen abwickeln?”
Hier geht es um Standards wie x402, MPP, UCP, ACP, die Mikrotransaktionen zwischen KI-Agenten und Webseiten ermöglichen. Für klassische B2B-Webseiten ist das aktuell die weniger relevante Ebene, wird aber für E-Commerce und Self-Service-Buchungen in den nächsten Jahren wichtiger.
Was wir auf dawema.com bestanden haben
Wir haben unsere eigene Webseite Punkt für Punkt geprüft. Hier die ehrliche Auswertung:
Discoverability: Bestanden. Wir haben eine vollständige Sitemap mit allen Service-Seiten, Stadt-Seiten und Blog-Beiträgen. Unsere robots.txt adressiert klassische Bots (Googlebot, Bingbot) und KI-Bots (GPTBot, ClaudeBot, PerplexityBot, Googlebot-Extended) einzeln. Die wichtigsten Endpunkte sind als HTTP-Link-Header annonciert.
Bot Access Control: Bestanden. Wir setzen den Content-Signal-Header mit ai-train=no, search=yes, ai-input=yes. Damit ist unsere Position klar: KI-Modelle dürfen unsere Inhalte für Antworten nutzen, aber nicht für Training verwenden.
Protocol Discovery: Bestanden. Wir haben unter /.well-known/agent-skills/index.json zwei konkrete Skills definiert (Live-Demo anfordern, Kontaktanfrage senden) mit Endpoint, Methode und erforderlichen Parametern. Unsere MCP-Server-Card unter /.well-known/mcp/server-card.json beschreibt DAWEMA als Service-Anbieter mit Capabilities, Sprache und Region. Ein API-Katalog unter /.well-known/api-catalog verlinkt unsere Endpoints mit OpenAPI-Beschreibungen.
Commerce: Aktuell nicht relevant für unser Geschäftsmodell. Wir bieten keine Self-Service-Buchung mit Direktzahlung an, sondern Beratungs- und Managed-Service-Verträge. Sollte sich das einmal ändern, integrieren wir die entsprechenden Standards. Realistisch ist das aber für eine B2B-Digitalagentur eher unwahrscheinlich.
Wo wir nachbessern mussten
Bei einem Punkt sind wir durchgefallen, obwohl wir ihn formal abgedeckt hatten: Content Accessibility / llms.txt.
llms.txt ist eine Markdown-Datei nach einem Standard von llmstxt.org, die einer KI in strukturierter Form mitteilt, welche Seiten welche Inhalte haben. Sie ist die agent-orientierte Ergänzung zur klassischen Sitemap. Wir hatten zwar eine Anfrage auf https://www.dawema.com/llms.txt mit HTTP-Status 200 beantwortet, aber unser Single-Page-App-Setup hat den Server-Routing-Fallback auf die generische HTML-Startseite aktiviert. Das heißt: eine KI hat unter /llms.txt zwar eine Antwort bekommen, aber kein strukturiertes Markdown, sondern das HTML der Startseite. Praktisch nutzlos.
Wir haben das im Rahmen dieses Selbsttests gefixt: Eine echte llms.txt mit Markdown-Struktur, gegliedert in Hauptseiten, Preisinformationen, Blog-Beiträge, Standorte, ein DAWEMA-spezifisches Glossar (für Begriffe wie Smart Transfer und Cold Transfer) und ausgewiesene Bot-Richtlinien. Eine KI, die unsere Webseite zum ersten Mal besucht, bekommt damit in 50 Zeilen einen kompletten Überblick über alles, was wir tun.
Das war für uns die wichtigste Lehre aus dem Test: Selbst wenn man vermeintlich alles richtig macht, lohnt der echte Audit. Statuscode 200 heißt nicht, dass die Antwort sinnvoll ist.
Checkliste für KMU-Webseiten
Wenn Sie selbst prüfen wollen, wie KI-ready Ihre Webseite ist, kommen Sie mit diesen acht Punkten in zwei bis drei Stunden Arbeit erstaunlich weit. Die Punkte sind nach Aufwand sortiert, vom schnellsten zum aufwändigsten.
1. robots.txt für KI-Bots erweitern (15 Min)
Ergänzen Sie Ihre vorhandene robots.txt um explizite Regeln für GPTBot, ClaudeBot, PerplexityBot und Googlebot-Extended. Setzen Sie zusätzlich den Content-Signal-Header mit der Kombination ai-train=no, search=yes, ai-input=yes, wenn Sie KI-Antworten ja, KI-Training nein wollen.
2. Sitemap auf Aktualität prüfen (10 Min)
Stellen Sie sicher, dass sitemap.xml alle wichtigen Seiten enthält, auch Blog-Beiträge und Branchen-/Stadt-Seiten. Reichen Sie die Sitemap in der Google Search Console ein, wenn Sie das nicht ohnehin schon tun.
3. ai.txt, security.txt und humans.txt anlegen (10 Min)
Kleine Komfort-Dateien unter /ai.txt, /security.txt und /humans.txt machen Ihre Webseite professionell wirken und beantworten häufige Fragen von Bots und menschlichen Besuchern, ohne dass diese durch die ganze Seite klicken müssen.
4. llms.txt mit strukturiertem Markdown anlegen (45 Min)
Erstellen Sie eine /llms.txt nach dem Standard von llmstxt.org. Inhalt: kurze Beschreibung der Webseite, Liste der Hauptseiten mit Links und einem Satz Beschreibung pro Seite, optionale Sektionen für Preise, Blog, Glossar und Bot-Richtlinien. Wichtig: prüfen Sie nach dem Anlegen, dass der Server die Datei wirklich ausliefert und nicht durch eine generische HTML-Fallback-Route ersetzt.
5. Strukturierte Daten nach Schema.org prüfen (60 Min)
Auf jeder Seite sollten passende Schema.org-Typen als JSON-LD eingebettet sein: Organization oder LocalBusiness auf der Startseite, Service auf Service-Seiten, FAQPage wo FAQs vorhanden sind, BreadcrumbList auf tiefer liegenden Seiten, BlogPosting auf Blog-Artikeln. Prüfen mit Google Rich Results Test.
6. Agent-Skills definieren (45 Min)
Wenn Ihre Webseite öffentliche API-Endpoints hat (Kontaktformular, Newsletter-Anmeldung, Buchungs-Anfrage), beschreiben Sie diese unter /.well-known/agent-skills/index.json. KI-Agenten können dann direkt mit Ihrer Webseite interagieren, statt mühsam HTML-Formulare zu parsen.
7. MCP-Server-Card und API-Katalog anlegen (60 Min)
Eine MCP-Server-Card unter /.well-known/mcp/server-card.json beschreibt Ihre Webseite als Service-Anbieter für das Model Context Protocol. Ein API-Katalog unter /.well-known/api-catalog verlinkt Ihre Endpoints mit OpenAPI-Beschreibungen.
8. Markdown Content Negotiation (fortgeschritten, 2-4 Stunden)
Auf Anfrage mit Header Accept: text/markdown sollte Ihr Server eine reine Markdown-Version der jeweiligen Seite ausliefern. Das ist aktuell die fortgeschrittenste Ebene, technisch komplexer (Server-Konfiguration plus Markdown-Generierung pro Seite), wird in den nächsten 6 bis 12 Monaten aber an Bedeutung gewinnen.
Was Sie ohne Technik-Wissen tun können
Falls Sie kein Web-Entwickler sind und keinen direkten Zugriff auf den Server haben, sind die ersten drei Punkte der Checkliste auch über die meisten CMS-Systeme oder mit einem freundlichen Hinweis an Ihre Webagentur erreichbar.
Punkt 1 (robots.txt) lässt sich in WordPress, TYPO3, Webflow oder Squarespace meistens direkt in den SEO-Einstellungen anpassen. Punkt 2 (Sitemap) wird in den meisten CMS automatisch generiert, muss aber bei Bedarf manuell um Branchen-Seiten ergänzt werden. Punkt 4 (llms.txt) ist eine einfache Markdown-Datei, die im Wurzelverzeichnis der Webseite abgelegt wird und in unter 30 Minuten erstellt ist.
Wenn Ihre Webagentur diese Begriffe nicht kennt, ist das ein klares Signal: Suchen Sie sich für den Bereich KI-Sichtbarkeit einen spezialisierten Partner. Die Investition rechnet sich in den nächsten 12 Monaten mehrfach, weil KI-Antwort-Plattformen einen wachsenden Anteil der Anbieter-Recherche übernehmen.
Realistischer Aufwand
Für eine durchschnittliche KMU-Webseite mit 10 bis 30 Seiten ist die KI-Ready-Konfiguration ein klar abgrenzbares Projekt von etwa zwei bis drei Arbeitstagen, plus laufende Pflege bei jedem neuen Inhalt. Diese Schätzung geht von einem erfahrenen Web-Entwickler mit modernem Tech-Stack und KI-gestützter Entwicklungsumgebung (z.B. Cursor, Claude Code, GitHub Copilot) aus. Wer klassisch ohne KI-Unterstützung entwickelt, kann etwa das Doppelte ansetzen. Mit ausschließlich manueller Recherche, ohne moderne Werkzeuge, kann es auch ein bis zwei Wochen dauern.
Wie messen Sie den Erfolg?
Erste Effekte (Sichtbarkeit in AI-Overview, Erwähnungen in ChatGPT-Antworten, einfachere Indexierung neuer Seiten) sind innerhalb von vier bis zwölf Wochen erkennbar. Das ist nur dann hilfreich, wenn Sie auch wissen, wie Sie das messen. Drei Methoden, die wirklich funktionieren:
1. Direkte AIO-Sichtprüfung über Google. Suchen Sie nach Ihren wichtigsten Money-Keywords. Wenn Google ein AI-Overview ausspielt, prüfen Sie die Quellen-Leiste rechts: Ist Ihre Webseite verlinkt? Anfangs nicht, im Idealfall nach 4 bis 8 Wochen schon. Das ist die direkteste Messung der KI-Sichtbarkeit, kostet nichts und braucht keine Tools.
2. KI-Modelle direkt fragen. Fragen Sie ChatGPT, Claude oder Perplexity beispielhaft: “Wer bietet KI-Telefonie für Handwerksbetriebe in Niedersachsen an?”. Schauen Sie sich die Quellen-Verweise an. Wenn Ihre Webseite zitiert wird, sind Sie messbar in der KI-Empfehlungs-Ebene angekommen. Wiederholen Sie das alle vier bis sechs Wochen, dann sehen Sie die Entwicklung.
3. Server-Logs auswerten. In den Access-Logs Ihres Servers können Sie sehen, welche User-Agents Ihre Webseite crawlen. Interessant sind GPTBot, ClaudeBot, PerplexityBot, Googlebot-Extended, Anthropic-AI. Wenn die Crawl-Frequenz dieser Bots nach der Optimierung deutlich ansteigt, wissen Sie, dass Sie sichtbar geworden sind. Tools wie Plausible, Matomo oder eine einfache Log-Analyse über grep reichen.
Für anspruchsvollere Messungen gibt es spezialisierte Tools wie Profound, Otterly oder DataForSEOs LLM-Mentions-API. Diese tracken systematisch, wie oft Ihre Marke in KI-Antworten erwähnt wird. Für die meisten KMU sind die drei oben genannten Methoden aber zunächst ausreichend.
Wer früh dran ist, hat in seinem Marktsegment einen klaren Vorsprung, weil aktuell noch sehr wenige Webseiten die fünf Kategorien konsequent abdecken.
Übergabe an die Praxis
Wenn Sie wissen wollen, wie Ihre Webseite in den fünf Kategorien abschneidet und wo konkret nachgebessert werden müsste, helfen wir bei einem strukturierten Audit. Wir prüfen Ihre Webseite Punkt für Punkt, zeigen Ihnen die konkreten Befunde und besprechen, welche Maßnahmen wirklich sinnvoll sind und welche Sie sich sparen können. Mehr Infos zu unserer Webentwicklung mit SEO-Fokus finden Sie auf der Webseiten-Service-Seite.
Testen Sie Ihre Webseite jetzt selbst
Geben Sie unten Ihre URL ein. Wir leiten Sie direkt zum offiziellen Cloudflare-Test weiter und sehen anschließend gemeinsam, wo Sie stehen. Mit Ihrer optionalen E-Mail-Adresse melden wir uns mit konkreten Verbesserungs-Vorschlägen, abgestimmt auf Ihr Ergebnis und Ihr Geschäftsmodell.
Möchten Sie Ihre Unternehmenswebseiten KI-Ready machen?
Wir prüfen Ihre Webseite Punkt für Punkt gegen den Cloudflare-Standard, beheben die Lücken und halten Sie laufend KI-ready. Persönlicher Ansprechpartner statt anonymes Ticket-System.